Time Series Data Analysis with Python
Deanna Spindler
IMSG at NCEP/EMC
Verification, Post-Processing and Product Generation Branch
Deanna Spindler
IMSG at NCEP/EMC
Verification, Post-Processing and Product Generation Branch
What is pandas?
The name comes from panel data, a statistics term for multidimensional datasets.
A high-perfomance open source library for tabular data manipulation and analysis
developed by Wes McKinney in 2008.
What does it do?
- Process a variety of data sets in different formats: time series,
heterogeneous tables, and matrix data. - Provides a suite of data structures:
- Series (1D => think columns),
- DataFrame (2D => think tables or spreadsheets)
- Panel (3D => a matrix of tables, I prefer to just use xarray)
- Missing data can be ignored, converted to 0, etc
- Facilitates many operations: subsetting, slicing, filtering, merging,
grouping, re-ordering and re-shaping - Integrates well with other Python libraries, such as statsmodels and SciPy
- Easily load/import data from CSV and DB/SQL
Example
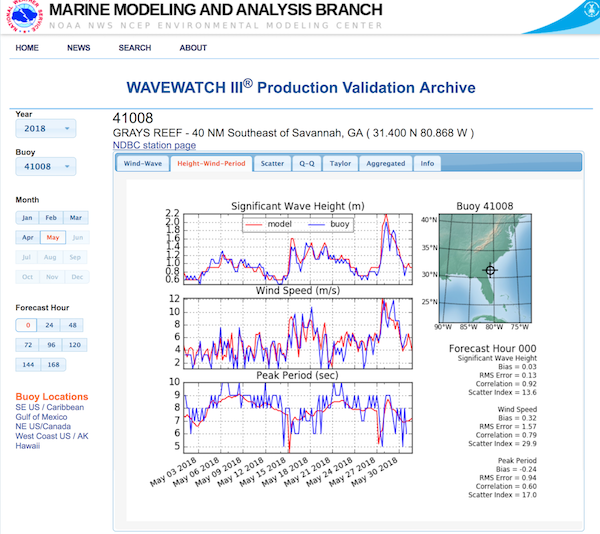
Using pandas DataFrames to validate WAVEWATCH III model output with NDBC buoy data.
- Creating DataFrames from ASCII files and remote data servers (OPeNDAP)
- DataFrame manipulations (selecting, merging, grouping)
- Basic descriptive statistics (RMS, Bias, Cross-Correlation, Scatter Index)
First things first
In [2]:
import matplotlib.pyplot as plt
import numpy
import pandas
import tarfile
import xarray
import netCDF4
from datetime import datetime,timedelta
from dateutil.relativedelta import relativedelta
Start by choosing a buoy and period of interest
In [3]:
buoyID='41008'
year=2018
month=6
Get the quality controlled NDBC data
In [4]:
url='https://dods.ndbc.noaa.gov/thredds/dodsC/data/stdmet/'+buoyID+'/'+ \
buoyID+'h'+str(year)+'.nc'
ncdata=xarray.open_dataset(url,decode_times=True)
Select the specific month of the year
In [5]:
startat=datetime(year,month,1)
stopat=startat+relativedelta(months=1)-relativedelta(days=1)
Subset the data to this time period, and make it a DataFrame
In [6]:
data=ncdata.sel(time=slice(startat,stopat)).to_dataframe()
Take a look at what is there
In [7]:
data.keys()
Out[7]:
Another way is to look at the first few rows of the DataFrame
In [8]:
data.head()
Out[8]:
I like to index on a datetime stamp, so let's reset the index
In [9]:
data=data.reset_index()
data.index=data['time'].dt.round('1H')
data.index.name='datetime'
In [10]:
data.head()
Out[10]:
The parameter names are long, and there are columns that are not used.
Let's fix that
In [11]:
params={'wind_dir':'udir',
'wind_spd':'u10',
'wave_height':'Hs',
'dominant_wpd':'Tp',
'longitude':'lon',
'latitude':'lat'}
dropkeys=[key for key in data if key not in params]
data.drop(dropkeys,axis=1,inplace=True)
data.rename(columns=params,inplace=True)
In [12]:
data.head()
Out[12]:
The Tp column does not look right...
In [13]:
data.Tp=data.Tp.astype('timedelta64[s]').astype(float)
In [14]:
data.head()
Out[14]:
Suppose we want to look at the data in a specific column,
or a Series:
In [15]:
Hs=data['Hs']
In [16]:
quartiles=numpy.percentile(Hs,[25,50,75])
hs_min,hs_max=Hs.min(),Hs.max()
In [17]:
print('Min: %.3f' % hs_min)
print('Q1: %.3f' % quartiles[0])
print('Median: %.3f' % quartiles[1])
print('Q3: %.3f' % quartiles[2])
print('Max: %.3f' % hs_max)
Get rid of the NaN's
In [18]:
Hs=data['Hs'].dropna()
In [19]:
quartiles=numpy.percentile(Hs,[25,50,75])
print('Min: %.3f' % Hs.min())
print('Q1: %.3f' % quartiles[0])
print('Median: %.3f' % quartiles[1])
print('Q3: %.3f' % quartiles[2])
print('Max: %.3f' % Hs.max())
It's nice to take a quick look at the data
In [20]:
Hs.plot(grid=True);

In the above example, we used the OPeNDAP server to get the quality controlled NDBC data.
If we wanted near-realtime data, we could get it the same way...
In [21]:
url='https://dods.ndbc.noaa.gov/thredds/dodsC/data/stdmet/'+buoyID+'/'+ \
buoyID+'h9999.nc'
ncdata=xarray.open_dataset(url,decode_times=True)
or another way
Unidata has been developing Siphon, a suite of easy-to-use utilities for accessing remote data sources.
In [22]:
from siphon.simplewebservice.ndbc import NDBC
df = NDBC.realtime_observations('41008')
df.head()
Out[22]:
Next, we need some model data for the same time period.
In this example, we are going to use the archived monthly buoy files:
NCEP_1806.tar.gz
MemberName:
- NCEP_1806_000
- NCEP_1806_024
- NCEP_1806_048
- NCEP_1806_072
- NCEP_1806_096
- NCEP_1806_120
- NCEP_1806_144
- NCEP_1806_168
In [23]:
ncep_cols=['id','year','month','day','hour','u10','udir','Hs','Tp']
In [24]:
w3data=pandas.DataFrame()
tar=tarfile.open('NCEP_1806.tar.gz')
In [25]:
for fcst in range(0,169,24):
memberName='NCEP_'+str(year)[2:]+"{:02n}".format(month)+ \
'_'+"{:03n}".format(fcst)
member=tar.getmember(memberName)
f=tar.extractfile(member)
frame=pandas.read_csv(f,names=ncep_cols,
sep=' ',
usecols=[1,3,4,5,6,7,8,9,10],
skipinitialspace=True,
index_col=False)
frame['datetime']=pandas.to_datetime(frame[['year','month','day','hour']])
frame=frame.drop(['year','month','day','hour'],axis=1)
frame=frame.set_index('datetime')
frame['fcst']=fcst
w3data=w3data.append(frame,ignore_index=False)
tar.close()
In [26]:
w3data.head()
Out[26]:
So now we have the NDBC data for buoy 41008 for June 2018, and the WW3 buoy data for all buoys for June 2018.
Our next step is to subset the w3data to just the data for buoy 41008.
In [27]:
buoyID='41008'
model=w3data[w3data.id==buoyID].copy()
In [28]:
model.head()
Out[28]:
In [29]:
model.fcst.unique()
Out[29]:
If interested in a single forecast:
In [30]:
m000=model[model.fcst==0]
In [31]:
m000.head()
Out[31]:
In [32]:
m000.fcst.unique()
Out[32]:
Recall the NDBC data
In [33]:
data.head()
Out[33]:
In [34]:
buoy=data.copy()
Now we can merge both the model and the NDBC data for the same buoy:
In [35]:
both=pandas.merge(model,buoy,left_index=True,right_index=True, \
suffixes=('_m','_b'),how='inner')
In [36]:
both.head()
Out[36]:
In [37]:
both024=both[both.fcst==24]
both024.head()
Out[37]:
In [38]:
plt.figure(dpi=100)
ax=plt.axes()
both[both.fcst==0].plot(ax=ax,y=['Hs_b','Hs_m'])
ax.grid(which='both')

So we have both the model and the NDBC data for the buoy
in the pandas DataFrame "both"
In [39]:
both.keys()
Out[39]:
Ready to calculate some basic stats...
First, see what methods the object has built-in
In [40]:
dir(both)
Out[40]:
In [41]:
methods=[x for x in dir(both) if not x.startswith('_')]
print(', '.join(methods))
In [42]:
both[both.fcst==0].describe()
Out[42]:
Help is available for the objects bound methods
In [43]:
help(both.corr)
Suppose we want to look at the correlation coefficient
for one forecast grouped by day
In [44]:
corr=both['Hs_m'][both.fcst==0].groupby(pandas.Grouper(freq='D')).corr(both['Hs_b'])
In [45]:
corr.head()
Out[45]:
Another way, is to select a parameter and forecast to validate
In [46]:
model=both[both.fcst==0]['Hs_m'].copy()
obs=both[both.fcst==0]['Hs_b'].copy()
To aggregate the data by day, we need to "group" the data
(think of looping through and collecting your data into chunks)
In [47]:
obsgrp=obs.groupby(pandas.Grouper(freq='D'))
Calculate some basic stats, grouped by day
In [48]:
diff=model-obs
diffgroup=diff.groupby(pandas.Grouper(freq='D'))
[v for v in diffgroup.groups.items()][:10]
Out[48]:
In [49]:
diff2group=(diff**2).groupby(pandas.Grouper(freq='D'))
count=diffgroup.count()
In [50]:
bias=diffgroup.mean()
bias.head()
Out[50]:
In [51]:
rmse=diff2group.mean()**0.5
rmse.head()
Out[51]:
In [52]:
scatter_index=100.*(rmse - bias**2)/obsgrp.mean()
scatter_index.head()
Out[52]:
Notice these are Series
It would be nice to have a DataFrame of the statistics
In [53]:
fcst=0
agg_stats=pandas.DataFrame({'Forecast':fcst,
'Bias':bias,
'RMSE':rmse,
'Corr':corr,
'Scatter_Index':scatter_index,
'Count':count})
In [54]:
agg_stats.head()
Out[54]:
Looks like something that might be nice to keep around?
In [55]:
import sqlite3
In [56]:
dbfile='my_stats_table.db'
conn = sqlite3.connect(dbfile,detect_types=sqlite3.PARSE_DECLTYPES)
agg_stats.to_sql('STATS',conn,if_exists='append')
conn.close()
To read it back in later
In [57]:
conn = sqlite3.connect(dbfile,detect_types=sqlite3.PARSE_DECLTYPES)
mystats=pandas.read_sql('select * from STATS',conn)
conn.close()
In [58]:
mystats.head()
Out[58]: